AI Data Platform¶
AI Data Platform은¶
Success
Data Platform은 NAVER의 방대한 데이터를 한 곳에 모아 효율적으로 활용할 수 있도록 데이터를 수집, 저장, 처리 및 분석할 수 있는 통합 플랫폼을 구축하여 NAVER 구성원에게 제공합니다.
네이버 내에서 AWS, GCP, Azure, Databricks, Snowflake등과 같은 역할을 수행합니다.
기능적으로 Data Platform은
- 데이터 통합 및 표준화를 통해 클라우드 기반 데이터 솔루션을 제공하고,
- 데이터 거버넌스를 강화하여 신뢰할 수 있는 데이터 활용 환경을 조성합니다.
- 메타데이터 관리와 자동화된 데이터 수집 시스템을 통해 대규모 데이터 자산을 체계적으로 관리하며, 비즈니스 가치를 극대화하는 데 기여합니다.
- 검색과 AI에 필요한 콘텐츠를 확보하고 활용하기 쉽도록 관리하는 업무도 수행합니다.
- 콘텐츠 관리를 통해 사내 담당자들이 필요한 콘텐츠를 쉽게 찾고 활용할 수 있도록 지원합니다.
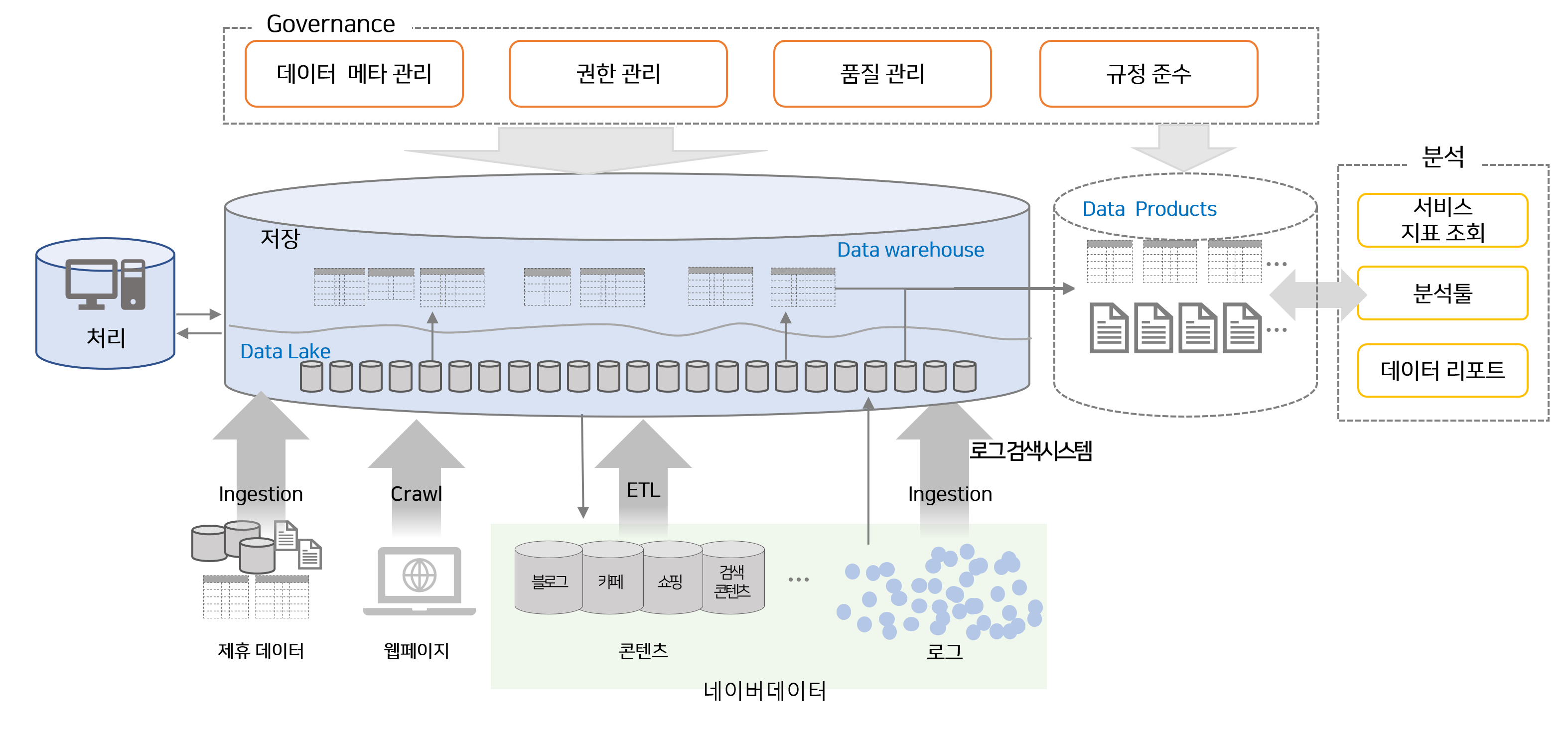
구체적으로 하는 일은¶
- 저장
- 조단위의 데이터 속에서 원하는 데이터를 빠르고, 쉽게 접근할 수 있도록 데이터를 저장합니다.
- 사용자 로그, 서비스의 컨텐츠, 웹수집 문서, 제휴 데이터등 다양한 종류와 특성을 가지는 데이터를 최적화된 형태로 저장합니다.
- 처리
- 급격하게 증가하는 트래픽의 데이터를 지연, 분산, 밸런싱등의 기법으로 사용자의 니즈에 맞게 처리되도록 합니다.
- 빠른 접근, 분산 처리등 다양한 사용 목적에 맞도록 데이터를 미리 가공해두어 비즈니스에 활력을 불어 넣습니다.
- 운영 중인 시스템의 일부에서 장애가 발생하더라도 처리가 지연되거나 처리가 멈추지 않도록 시스템을 설계, 운영, 개발합니다.
- 제휴데이터 ingestion
- 데이터 수요를 파악하여 소싱, 계약, 법무 검토, 수급하는 일련의 과정을 프로세스화 하고 이에 맞춰 실제 DB를 수급합니다.
- Web Crawl
- 수 십억 규모의 다양한 문서를 수집하고 효과적으로 색인될 수 있도록 가공합니다.
- 스팸 및 저품질 문서를 지능적으로 분류하고 검색을 위한 최적의 문서를 선별하여 색인합니다.
- 콘텐츠 ETL / ELT
- 대용량 데이터를 대규모 분산환경에서 스트리밍, 배치 방식으로 처리하여 검색 및 주요 서비스에서 활용할 수 있도록 가공합니다.
- Data Governance
- 데이터와 관련된 규정/법규를 실제로 데이터를 사용하는 환경에 사용/관리-프로세스로 구체화 합니다.
- 데이터 사용/관리 - 프로세스를 데이터 플래폼의 기능으로 구현되도록 제안합니다.
- 데이터 사용/관리 - 프로세스가 잘 준수되고 있는지 확인하고 보완하는 감사활동을 합니다.
주요 기술¶

- 분산 데이터 저장 - HBase, Kafka, MongoDB, mysql, redis, Elasticsearch
- 클라우드 & 분산 시스템 - K8S (서버 운영 포함), Spring Cloud, Yarn, Docker, Network server, 분산 환경 보안 전문가
- 개발 언어 & 프레임워크 - Python, Java, Scala, Golang, C++, C / Kotlin, Javascript, Node.js, React (TypeScript 포함), Spring / huggingface transformer library, freemarker
- 빅데이터 처리 & 분석 - Hadoop (Eco System 포함), Spark, Hive, Trino(Presto), Hudi, ELK (운영 포함), Logstash, Airflow, flink, ETL
- 기타 - Linux, Jenkins, Git (기반의 코드리뷰), Webpack, headless browser
참고자료¶
컨퍼런스 참여¶
- 로그 수집
- [Deview 2017] 백억 개의 로그를 모아 검색하고 분석하고 학습도 시켜보자: 로기스
- [Deview 2019] 네이버 로그를 지탱하는 힘
- [DAN 2025] 하루 수백억 건을 처리하는 똑똑한 로그 파이프라인 만들기: 비용·성능·안정성 삼박자
- AI
- [Deview 2017] 빅데이터를 위한 분산 딥러닝 플랫폼 만들기
- [Deview 2018] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기
- [Deview 2019] 외산 클라우드 없이 AI 플랫폼 제공하기: features, training, serving, and AI Suite
- [Deview 2020] 손쉽게 ML 라이프사이클을 다룰 수 있는 MLOps
- [Deview 2021] AiSuite : Kubeflow를 통해 더 나은 AI 모델 서빙과 MLOps 실현하기
- [Deview 2021] 대규모 자연어처리 모델 서빙 경험기
- [Dan 2024] AI 플랫폼에 딱 맞는 STOAGE : AISUITE에 JUICEFS 적용기
- [OpenInfra Summit Asia 2024] Storage JuiceFS Appliances for AI Platforms
- 연산/처리
- [Deview 2018] C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터
- [Deview 2019] 대용량 멀티테넌트 시큐어 하둡 클러스터를 시행착오 없이 만들기
- [Deview 2019] 대규모 클러스터 모니터링 도전기: 모니터링, 어디까지 알아보고 오셨어요? Cluster level 부터 User level까지
- [Deview 2020] 대용량 멀티테넌트 시큐어 하둡 클러스터 운영 경험기
- [Deview 2021] 초대용량 멀티테넌트 시큐어 하둡 클러스터 성장통 경험기
- [DAN 2025] IDC Seamless HDFS: IDC의 한계를 넘어 도달한 데이터 통합의 세계
- Query 프로세싱 * [Deview 2023] CQuery : 우당탕탕 Trino와 썸타기
- [Trino Summit 2023] Opening up the Trino Gateway with the project maintainers
- [NAVER DAN24] CQueryHub: Data Warehouse입니다. 근데 이제 Flink와 Iceberg를 곁들인
- [Trino Summit 2024] Many clusters and only one gateway
- 저장
- [Deview 2015] Hbase consistent secondary indexing
- [Deview 2017] HBase 기반 검색 데이터 저장소
- [Deview 2019] 네이버 로그를 지탱하는 힘
- [Deview 2021] 네이버 최대의 데이터 저장소 운영기 (HBase Locality기반 운영기)
- [Deview 2023] 바닥까지 파보는! Hbase random read 성능 개선기
- [Dan 2024] 실전에서 레벨업! HBASE 디스크 읽기 성능 개선기
- 데이터 거버넌스
- [Deview 2021] AIDA Project : 전사 통합 데이터 거버넌스와 권한 관리
기술 블로그 ¶
- [Naver D2] 멀티테넌트 Hadoop 클러스터 운영 경험기
- [Naver D2] 딥러닝 분산 플랫폼, C3DL
- [Naver D2] KafkaProducer Client Internals
- [Naver D2] KafkaConsumer Client Internals
- [Naver D2] Kafka NetworkClient Internals
- [Naver D2] HDFS 쓰기 파이프라인을 활용한 HBase의 WAL 쓰기 최적화
- [JuiceFS blog] NAVER, Korea's No.1 Search Engine, Chose JuiceFS over Alluxio for AI Storage
- [NAVER D2] AI 플랫폼을 위한 스토리지 JuiceFS 도입기
- [NAVER D2] JuiceFS: 오브젝트 스토리지를 활용하는 HDFS 호환 분산 파일 시스템
- [NAVER D2] 비용, 성능, 안정성을 목표로 한 지능형 로그 파이프라인 도입
조직문화¶
- [네피셜] 건초 더미에서 바늘 찾게 해주는, 그런 개발자 이야기
- [네피셜] “이거… 제가 새로 만들어봐도 돼요?”라고 물어 본 주니어 개발자가 들은 대답
- [네피셜] 해커톤 출신 네이버 검색 개발자가 생각하는, 냉장고와 네이버 검색 저장소
오픈소스 기여¶
- 연산/처리
- YARN-8693 Add signalToContainer REST API for RMWebServices
- YARN-8761 Service AM support for decommissioning component instances
- YARN-9197 NPE in service AM when failed to launch container
- YARN-9307 node_partitions constraint does not work
- YARN-9521 RM failed to start due to system services
- YARN-9583 Failed job which is submitted unknown queue is showed all users
- YARN-9633 Support doas parameter at rest api of yarn-service
- YARN-9647 Docker launch fails when local-dirs or log-dirs is unhealthy.
- YARN-9691 canceling upgrade does not work if upgrade failed container is existing
- YARN-9703 Failed to cancel yarn service upgrade when canceling multiple times
- YARN-9719 Failed to restart yarn-service if it doesn’t exist in RM
- YARN-9731 In ATS v1.5, all jobs are visible to all users without view-acl
- YARN-9790 Failed to set default-application-lifetime if maximum-application-lifetime is less than or equal to zero
- YARN-9905 yarn-service is failed to setup application log if app-log-dir is not default-fs
- YARN-9921 Issue in PlacementConstraint when YARN Service AM retries allocation on component failure.
- YARN-9953 YARN Service dependency should be configurable for each app
- YARN-9837 YARN Service fails to fetch status for Stopped apps with bigger spec files
- YARN-9986 signalToContainer REST API does not work even if requested by the app owner
- YARN-10021 NPE in YARN Registry DNS when wrong DNS message is incoming
- YARN-10119 Cannot reset the AM failure count for YARN Service
- YARN-10034 Allocation tags are not removed when node decommission
- YARN-10196 destroying app leaks zookeeper connection
- YARN-10184 NPE happens in NMClient when reinitializeContainer
- YARN-10203 Stuck in express_upgrading if there is any component which has no instance
- YARN-10206 Service stuck in the STARTED state when it has a component having no instance
- YARN-10262 Support application ACLs for YARN Service
- YARN-10267 Add description, version as allocationTags for YARN Service
- YARN-10305 Lost system-credentials when restarting RM
- HDFS-14434 webhdfs that connect secure hdfs should not use user.name parameter
- HADOOP-16441 if use -Dbundle.openssl=true, bundled with unnecessary libk5crypto.*
- HIVE-22126 hive-exec packaging should shade guava
- HIVE-23153 deregister from zookeeper is not properly worked on kerberized environment
- HIVE-24590 Operation Logging still leaks the log4j Appenders
- HIVE-23164 Server is not properly terminated because of non-daemon threads
- TEZ-4188 Link to NodeManager Logs of Home and DAG details doesn't consider yarnProtocol
- TEZ-4205 Support RM delegation token
- HIVE-23954 count(*) with count(distinct) gives wrong results with hive.optimize.countdistinct=true
- HIVE-23458 Introduce unified thread pool for scheduled jobs
- HIVE-24713 HS2 never shut down after reconnecting to Zookeeper
- HIVE-24948 Enhancing performance of OrcInputFormat.getSplits with bucket pruning
- HDFS-12204 Dfsclient Do not close file descriptor when using shortcircuit
- https://issues.apache.org/jira/browse/HADOOP-17859
- https://issues.apache.org/jira/browse/YARN-10895
- https://issues.apache.org/jira/browse/YARN-10892
- https://issues.apache.org/jira/browse/YARN-10892
- https://issues.apache.org/jira/browse/HADOOP-18639
- Query 프로세싱
- https://github.com/trinodb/trino/pull/10561
- https://github.com/trinodb/trino/pull/16589
- https://github.com/trinodb/trino/pull/20376
- https://github.com/trinodb/trino/pull/15389
- https://github.com/trinodb/trino/pull/15380
- https://github.com/trinodb/trino/pull/1330
- https://github.com/trinodb/trino-go-client/pull/14
- https://github.com/trinodb/trino-go-client/pull/7
- https://github.com/trinodb/trino-gateway/pull/423
- https://github.com/trinodb/trino-gateway/pull/766
- https://github.com/trinodb/trino-gateway/pull/531
- https://github.com/trinodb/trino-gateway/pull/464
- https://github.com/trinodb/trino-python-client/pull/537
- 저장
- HBASE-16299 Update REST API scanner with ability to do reverse scan
- HBASE-16326 CellModel / RowModel should override 'equals', 'hashCode' and 'toString'
- HBASE-23561 Look up of Region in Master by encoded region name is O(n)
- HBASE-24130 rat plugin complains about having an unlicensed file.
- HBASE-24348 CloseChecker should think Pressure Aware Throughput Controller
- HBASE-23968 Periodically check whether a system stop is requested in compaction by time.
- HBASE-24652 master-status UI, make date type fields sortable
- HBASE-26895 on hbase shell, 'delete/deleteall' for a columnfamily is not working
- HBASE-26901 delete with null columnQualifier occurs NullPointerException when NewVersionBehavior is on
- HBASE-27219 Change JONI encoding in RegexStringComparator
- HBASE-28563 Closing ZooKeeper in ZKMainServer
- HBASE-11794 StripeStoreFlusher causes NPE
- HBASE-13473 deleted cells come back alive after a stripe compaction
- HBASE-29254 StoreScanner returns incorrect row after flush due to topChanged behavior
- AI
- https://github.com/kubeflow/manifests/pull/1877
- https://github.com/kubeflow/pipelines/pull/5293
- https://github.com/kubeflow/pipelines/pull/5552
- https://github.com/kubeflow/kfserving/pull/1361
- https://github.com/NVIDIA/deepops/pull/893
- 기타
- https://github.com/ilum-cloud/marquez/pull/8
- https://github.com/airlift/airlift/pull/1257
- https://issues.apache.org/jira/browse/AMBARI-25624
- 그외 다수